
Understanding intelligence: Simplex views on complex systems
A conversation with Adam Shai and Paul Riechers, co-founders of Simplex


Interpretability is one of the biggest open questions in artificial intelligence. In other words, what’s going on inside these models?
Adam Shai and Paul Riechers are the co-founders of Simplex, a research organization and Astera grantee, focused on unpacking this question. They’re working to understand how AI systems represent the world — a critical component of AI safety with major societal implications.
We sat down with them for a conversation on internal mental structures in AI systems, belief-state geometries, what we can learn about intelligence at large, and why this all urgently matters.
How did you both decide to leave academic tracks to start Simplex?
Adam:
My background was in experimental neuroscience. I spent over a decade in academia — during my postdoc, I was training rats to perform tasks, recording their neural activity, and trying to reverse-engineer how their brain neural activity leads to intelligent behavior. I thought I had some handle on how intelligence works.
During that time, ChatGPT came out. I was stunned at its abilities. I started digging into the transformer architecture, the underlying technology that powers ChatGPT, and I was even more shocked. The transformer architecture didn’t intuitively tell a story about its behavior.
I realized two things at that time. The first was unsettling. I’d thought of myself as a neuroscientist with a pretty good intuition for the mechanistic underpinnings of intelligence. But that intuition seemed to be completely incorrect here.
The second was even scarier. What are the societal implications for having this kind of intelligence at scale? The social need to understand these systems, and to understand intelligence more broadly, is more important than it's ever been before. At the same time, there's also this new opportunity to understand intelligence, not just for artificial systems, but maybe even for humans — to really learn more about our own cognition.
Paul:
I came from a background in theoretical physics, thinking about the fundamental role of information in quantum mechanics and thermodynamics, with a recurring theme of predicting the future from the past — how to do that as well as possible. That’s traditionally a core part of physics — your equations of motion help you predict how the stars move, for example. But it also gets into chaos theory, where you have very few details available to predict a chaotic, complex world. And you quickly get to the ultimate limits of predictability and inference.
At the time, this had nothing to do with neural nets and I hadn’t paid much attention to them — they work on predictions of tokens, or chunks of words — but they seemed unprincipled compared to the beautiful theory work I was doing in physics. But then they started working — and not just working, but working really well. To the point where I started feeling uneasy about the future societal implications.
And given my background in prediction, I then started wondering what it might look like to apply the components of a principled mathematical framework to what these neural networks are doing. What are their internal representations? What emergent behaviors can we anticipate? I linked up with Adam and we tried the smallest possible thing we could. And it worked better than we could have hoped for.
That’s what grew into Simplex — we realized there wasn’t really a space for this yet, a program to solve interpretability all the way, and there’s a lot to build on. Our mission at Simplex is to develop a principled science of intelligence, to help make advanced AI systems compatible with humanity. It’s been a really fun collaboration and it’s leading us to a better understanding of how AI models are working internally, which then gives insight into what the heck we’re building as AI systems scale. We’re optimistic these insights can help create more options and guide the development of AGI towards better outcomes for humanity.
You’ve described AI models not as engineered systems, but as ‘grown’ ones…what do you mean by that?
Adam:
Yeah, I think this is an under-appreciated aspect of this new technology. Most people assume they’re engineered programs. But they’re not like other software programs — they’re more like grown systems. Engineers set up the context and rules for growing, and then press play on the growing process. What they grow into and the path of their development isn’t engineered or controlled.
And so we’ve ended up with these systems that are incredibly powerful. They are writing, deploying, and debugging code, solving complex mathematical problems at near-human expert levels, and really peering over the edge of what humans can do. This isn’t a future scenario, that’s where we are right now. But we have very little idea of how these systems work internally. And that’s a problem — a lot of safety issues come from this unknown relationship between the behaviors of these systems and their internal processing.
Paul:
For example, AI systems are increasingly showing signs of deception, especially when under safety evaluation. Some actively evade safeguards, while others generate plausible explanations that don’t match their true reasoning. These mismatches between external behavior and internal thought process of the AI highlight the need to understand the geometry and evolution of internal activations — without it, we’re largely blind to the system’s intentions.
So how do you go about studying that internal structure?
Paul:
We’ve come up with a framework that started from a part of physics called computational mechanics — basically exploring the fundamental limits of learning and prediction by asking what features of the past are actually useful in predicting the future. And then we leveraged this structural part, which looks at the geometric relationship between these different features of the past.
Adam:
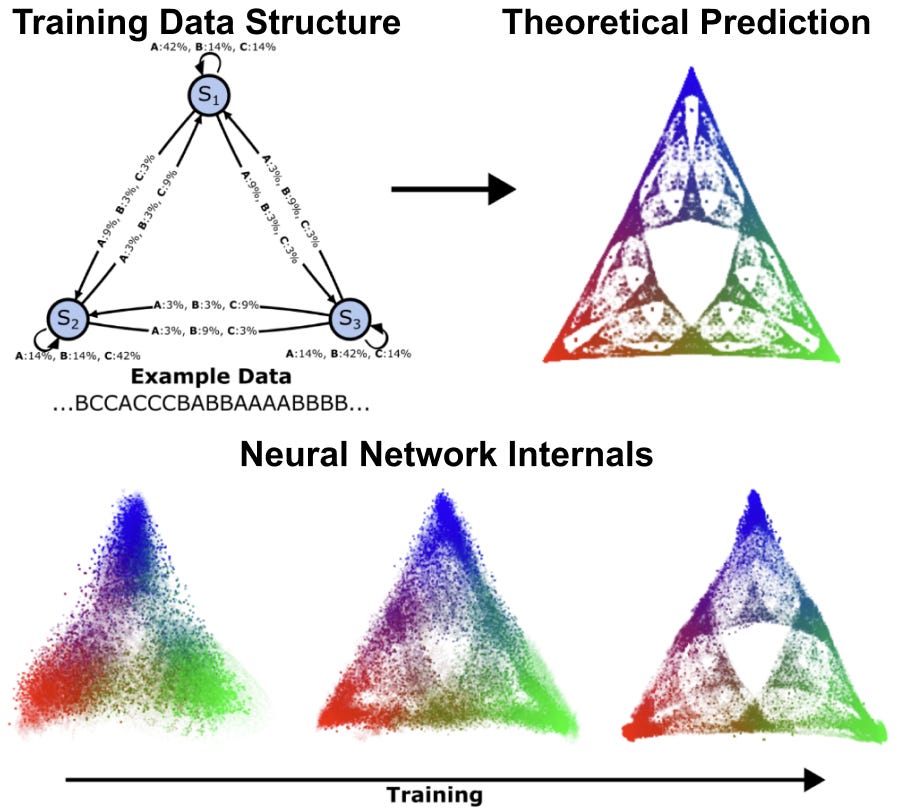
We discovered that AI models organize information in consistent patterns, like a mental map consisting of specific types of shapes and structures. We call these patterns belief-state geometries, because fundamentally they are the AI model’s internal representation of what’s going on in the world. These patterns often have repeated structure at different scales, leading to intricate fractals. For instance, when we studied a transformer learning simple patterns, we found it creates a fractal structure that looks like a Sierpinski triangle — where each point represents a different belief about the probabilities of all possible futures. As the AI reads more text, it moves through this geometric space, updating its beliefs in mathematically precise ways that our theory predicted. Now that we have this framing, we can start to anticipate those structures. We can start to predict where in the network to look for them, and test whether our theories hold and we can refine them. It’s a huge shift from just poking around and hoping something interpretable falls out.
How does this differ from what others in the field are doing?
Adam:
There’s a field of research called interpretability, which is trying to understand how the internals of AI systems carry out their behavior. It is very similar to the type of neuroscience I used to do, but applied to AI systems instead of to biological brains. There’s been an enormous amount of progress over the last few years, and a lot of interest because of the growth of LLMs. In many ways interpretability has even been able to surpass the progress in neuroscience.
However, the approach is often highly empirical. Despite all the progress, the field is often left wondering to what extent the findings apply to other situations that weren’t tested, or if their methods are really robust, or how to make sense of their findings. In a lot of ways, we still don’t really know what the thing we are looking for is, exactly. What does it look like to understand a system of interacting parts (whether they be biological or artificial neurons) whose collective activity brings about interesting cognitive behavior? What’s the type signature of that understanding?
Paul:
What’s missing is a theoretical framework to guide empirical approaches. Our unique advantage is that, by taking a step back and really thinking about the nature of computation in these trained systems, we can anticipate the relationship between the internal structure and behaviors of AI systems. One of the most important points of this framework is that it is both rigorous and also amenable to actual experiments. We aren’t doing theory for theory’s sake. The point is to understand the reality of these systems. So it’s this feedback loop between theory and experiment that allows us to make foundational progress that we can trust and build on in a way that’s different from most other players in the field.
How might this type of geometric relationship between features of the past differ across sensory modalities — language, images, sounds, etc.? Is there a difference between how it works in humans and AI systems?
Paul:
This is an area we’re really interested in exploring more. There’s some evidence that suggests that neural networks trained on different modalities converge on similar geometric representations of the world. It seems to be that no matter which modalities an intelligent system uses to interact with the world, it’s trying to reconstruct the whole thing.
It raises some fascinating questions — to what extent are different modalities and even different intelligences converging on a shared sense of understanding? Is there a unique answer to what it's like to be intelligent? And if so, maybe that's useful for increasing the bandwidth of communication among different intelligent beings? And if not — if each intelligent thing understands the world in a valid but incompatible way — that’s maybe not great for hopes of us being able to come to a shared understanding and aligned goals? So that’s one thing we’re very interested in as we learn how models represent the world.
Adam:
I think there’s also a really interesting opportunity to understand ourselves better. It opens up this entire new field of access to understand intelligence. If you’re a neuroscientist, you no longer have to decide between studying a human brain and having very low access, or studying a rat and having more access at the expense of cognitive behavior. With neural networks, you can look at everything.
We can even potentially engineer neural networks to whatever level of complexity, whatever kind of data, and whatever kind of behavior we want to study, even at a level that exceeds human performance. And it opens up this new, really fast feedback loop between theory and experiment — it’s an unprecedented opportunity to understand intelligence in a very general sense.
Given your work is really about understanding intelligence more broadly, beyond just AI systems, where do you hope it will lead?
Adam:
Previously, there’s been no framework that gives us any kind of foothold to talk about this relationship between internal structure and outward behavior. We’re trying to build this kind of principled framework for how to think about these questions. It could be applied to LLMs in order to understand them and make them safer. But the general framework also has the promise of being applicable to other systems where we're trying to understand the relationship between the internal structure and outward behavior. And those other systems could be biological brains.
Paul:
Part of the value we’re providing is also a shared understanding, or ground truth for how these systems work. Today, people have different opinions about what these systems are — some maintain that the current AI paradigm will fall short of AGI or superhuman intelligence, while a growing contingent finds it obvious that you can bootstrap a minimal amount of intelligence to become superhuman across the board. More concerning is that informed technologists disagree about whether ASI (artificial superintelligence) will most likely lead to human extinction or flourishing. Even among experts, people really talk past each other. AI safety may or may not be solvable. Part of our work is to establish a scientific foundation for coming to a consensus on that, and identifying paths forward.
I’m hopeful that we can elevate the conversation by creating a shared understanding of what the science says, so it’s no longer doomers and optimists, but rather people working together to figure out the implications of what we’re building, and how we steer towards the kind of future we want. It’s a lofty goal but we think it’s possible. As we continue to build our understanding of structures in our own networks, we’ll hopefully be able to leverage that for a societal conversation for what it is we want to be building towards.
Learn more about Simplex's insights and follow their technical progress.