
What Scientists Said: Results from Astera's First Essay Competition

Astera recently hosted its first essay competition, focused around metascience. This competition was always more about starting a conversation than finding a bunch of perfect solutions. We wanted to hear from working researchers, not policy experts or administrators, about the structural problems they actually run into, described concretely enough that someone could do something about them. We also wanted that conversation to initiate a more public dialogue, which is why we required all submissions to be posted openly before being submitted to us.
We weren’t sure if this requirement would be a major blocker, but nearly 200 scientists openly published their ideas. Many of the essays attracted real engagement through comments sections and social media. We read every piece as well as the threads in which other researchers asked questions, offered suggestions, pushed back, or shared their own versions of the same problem. That was exactly what we were hoping to see. There’s something different about a scientist putting their name on a specific critique of how their field operates versus signing a letter or venting in a survey, and watching that happen across disciplines was genuinely encouraging.
Below we’re sharing some of the high level takeaways and the set of researchers that we are giving cash awards to. We’ve also reached out to a few submissions ourselves to explore potential paths forward that we could help support. And we’ve been sharing the essays with other funders and policymakers as well, in case that can help influence their strategic priorities at this critical moment in time.
By the numbers

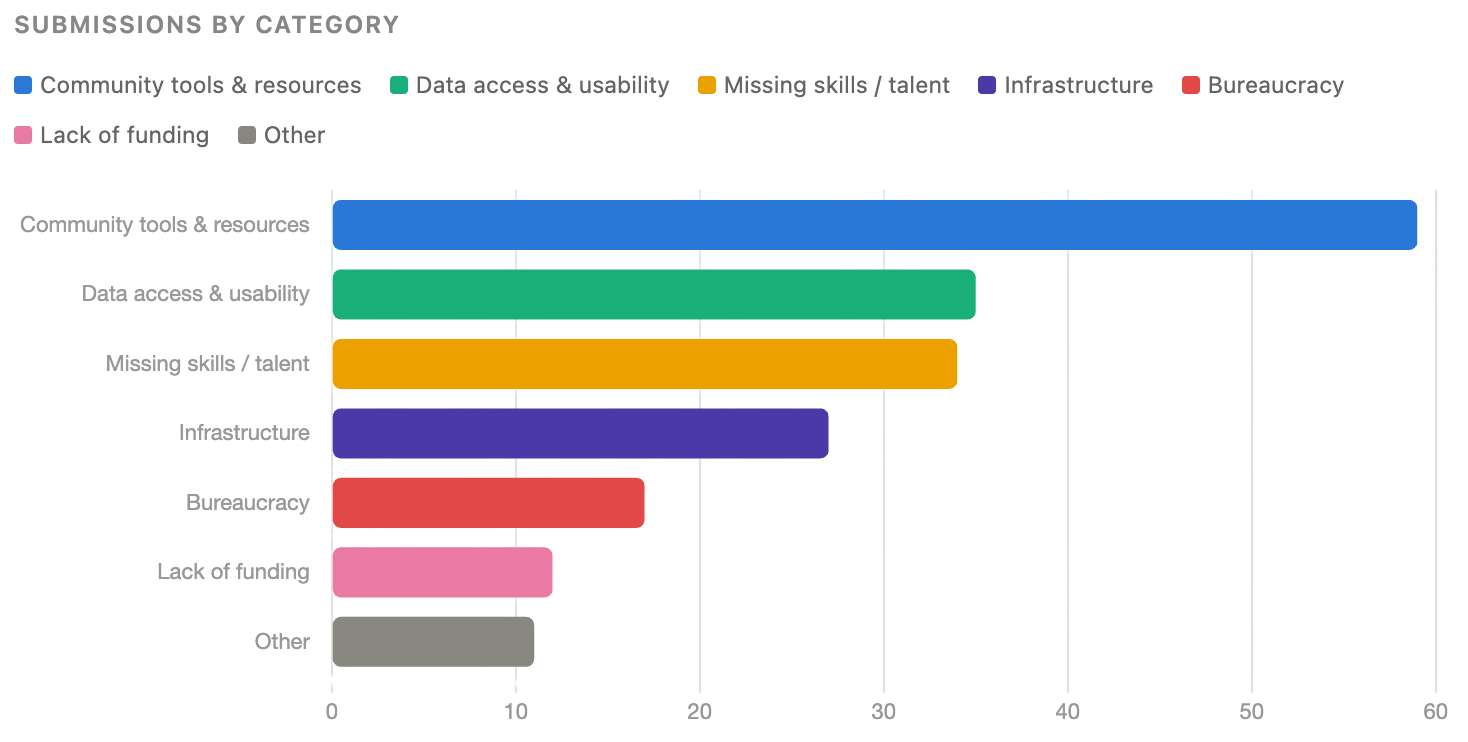
We initially organized the essays into different broad thematic categories, which was informative. Whatever scientists are most frustrated about right now, it isn’t only about roadblocks happening at the individual level. “Community tools and resources” was the most common at 30%. Essential infrastructure for sharing, maintaining, and building on existing work and data is also badly underdeveloped.
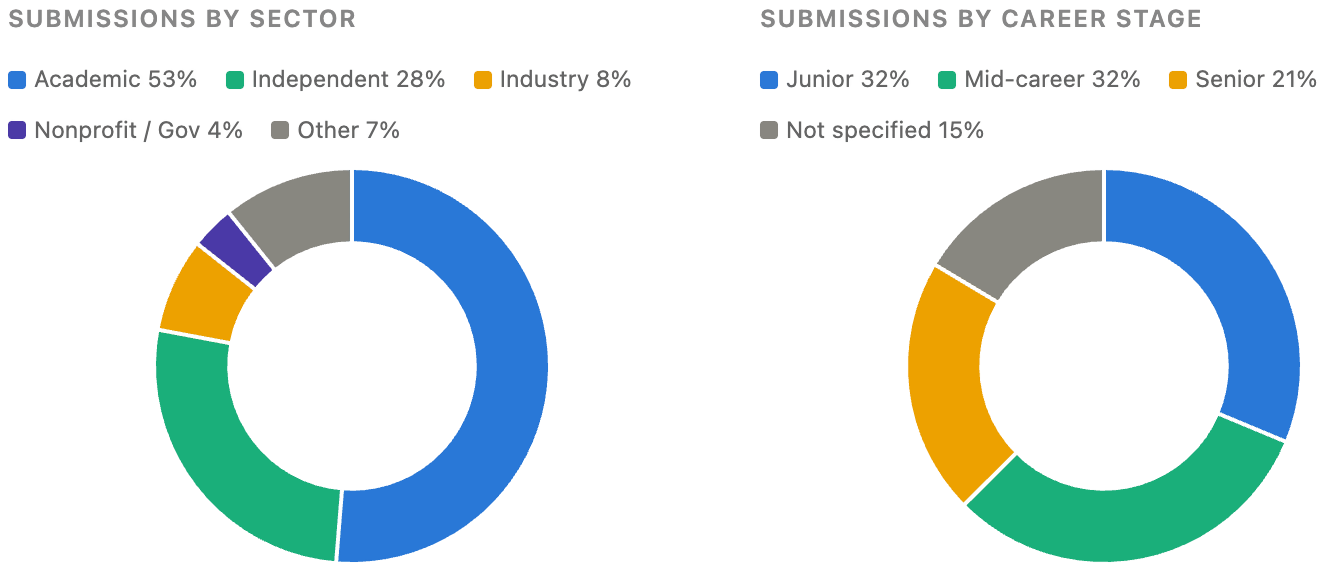
In terms of the submitters themselves, essays came from academic researchers (53%), independent researchers (28%), industry scientists (8%), and nonprofit and government researchers (4%). Junior and mid-career researchers each contributed 61 essays, compared to 41 from senior researchers. We were delighted to hear from so many people closer to the beginning of their careers who are optimistic about the opportunity for systemic change. Ultimately, while many of the proposed solutions would benefit from funding, their successful execution would need a more bottom-up approach from researchers on the ground.
A note on AI usage
We decided not to allow AI usage to factor into scoring, as we believe this is a new reality that can be embraced for good. Using AI as a writing tool can help researchers whose first language isn’t English, or who are simply too busy to agonize over prose. We think it probably helped propel ideas that might otherwise have been harder to submit or read.
After the competition and judging closed, we ran all submitted essays through Pangram as a retrospective check. Interestingly, we found that essays we triaged out earlier tended to show higher AI usage, while the finalist pool was mixed. We suspect that AI usage wasn’t always the cause of weaker essays, but possibly a correlate of them, i.e. submissions that didn’t have strong underlying ideas also seemed to rely more heavily on AI to flesh them out.
What scientists said
The top five broad themes below came from reading across all 195 essays.
1. Coordination failure
The most common frustration, cutting across nearly every category, was coordination failure. Not a shortage of ideas or data or even funding, but the absence of any mechanism for doing collectively what no individual lab or team can do alone. Valuable scientific assets like datasets, methods, null results, years of accumulated know-how lack shared infrastructure for sharing, maintaining, and learning from them. This category, which accounted for more than half the submissions, includes issues around community tools, data access, infrastructure. The essays in this bucket also tended to be unusually specific about what was missing and why, which was helpful for brainstorming fundable solutions.
Go here to see the catalog of submissions related to coordination failure →
2. Data issues
The state of scientific data came up enough to deserve its own category, especially given the increasing importance of data for any AI-related work. The main issues revolved around the quality and usability of the data itself (inconsistent formats, missing metadata, lack of standards and useful benchmarks). There’s a big need for more useful crosstalk between different datasets so that scientists can learn more from work across groups or measurement types. It’s clear that scientists have been navigating these problems for a long time, but the cost of not fixing them keeps going up. Before funding more data, what can we do to clean up and utilize what’s already available to us?
Go here to see the catalog of submissions related to data →
3. Scientific training
Training came up in 34 essays, not as a complaint about individual researchers but as an observation about what the PhD and postdoc pipeline systematically fails at, especially as the technological landscape changes. Specific skillsets that were repeatedly mentioned were ones around statistical rigor, computational analyses, cross-disciplinary fluency, and more connections to utility and translatability for greater impact.
Go here to see the catalog of submissions related to training →
4. Incomplete artifacts
The cost of invisibility was a fourth recurring thread. For example, untested ideas aren’t shared, null results often don’t get published, methods aren’t very reusable, and datasets get reused infrequently. A lot of the most actionable essays weren’t proposing new research programs; they were proposing the knowledge infrastructure that would make existing research compoundable.
Go here to see the catalog of submissions related to capturing the full scientific process →
5. Modernization
Finally, AI understandably came up a lot, and the essays we found most useful were the ones that treated it as a forcing function rather than the ultimate solution. The most compelling arguments were around structural gaps that have always existed and are now more costly to ignore and more possible to fix. If your data isn’t useful or interoperable, AI-assisted analysis doesn’t fix that. Without thinking more deeply about what data and data formats are most valuable to particular goals, scientists will still run into the same walls faster and potentially at greater cost.
Go here to see the catalog of submissions related to being more AI-ready →
Our review process
Below are a few notes about how we selected the finalist pool. Feel free to skip to the next section if you’d rather just read more about the winning submissions.
In short, we reviewed all 140 essays that passed initial triage against several dimensions:
Was the submitter an active scientist? (defined as a researcher currently working on a novel research problem)
How clearly and specifically the scientific bottleneck was described?
How deeply the essay understood the structural reasons it persists beyond a single researcher or group?
Is there a plausible pilot to test the hypothesis?
And of course basic properties we requested, such as length and the existence of a public posting.
A note on format: the 3-page limit made author participation easier, but it also limited how developed the proposal could be. Articulating a deep problem and solution in three pages is hard, and in a few cases we could see the outlines of a stronger argument that required more space to flesh out. We did have to triage submissions that ran significantly longer, because comparing a 5-page essay with a 3-page one in a competition context isn’t fair. That said, we read all of them and may follow up on some of the longer ones that had compelling ideas.
The top 30 clustered into eight areas, which we presented to our judges for review and discussion: biological data standards and integration, clinical translation and healthcare (the single largest cluster), neuroscience methods and infrastructure, publication systems and knowledge, funding structures and research practice, data access and privacy barriers, interdisciplinary and cross-domain work, and specialized technical bottlenecks. Clinical translation being the largest was somewhat surprising; there were more specific, structurally sophisticated proposals about the gap between research findings and clinical practice than we expected.
The winners
When the panel finished its review, there wasn’t a clear top first-place essay. That wasn’t necessarily a failure of the judging, but perhaps a feature of the shorter length. We also learned that we embrace disagreement across judges, and our award structure should better reflect that.
Unsurprisingly, there was a lot of debate amongst our evaluators on what ideas could hold the most promise. Rather than award a first prize somewhat arbitrarily, we decided to forgo it and instead recognize more essays at the second and third prize level, which meant increasing our total prize budget. The eight essays below were the ones that most consistently combined a precise diagnosis with a credible path to doing something about it.
2nd Prize
Shaamil Karim
Shaamil is the founder of Atlas Discovery, which builds AI models to improve the success rate of drugs in clinical trials. Virtual cell models are all the rage right now, but they’re limited in a few ways. Shaamil discusses the need for including data that informs on clinical outcomes.
Jaeeon Lee
Jaeeon is a postdoctoral researcher at Harvard, studying how animals learn to generalize across changing environments, combining electrophysiology, fiber photometry, and computational modeling. Jaeeon discusses how systems neuroscience has accumulated a lot of competing theoretical frameworks, but no mechanism for forcing them to make predictions on the same data.
Peter Koo
Peter is an Associate Professor at Cold Spring Harbor Laboratory, where his lab develops interpretable machine learning systems for understanding gene regulation. Scientific fields often have the resources and the clear opportunities to build foundational shared datasets, but no mechanism for deciding collectively what to prioritize. Peter’s essay framed this as a governance problem rather than a funding problem.
Prashant Garg
Prashant is a Research Associate at Cambridge who studies science and innovation using machine learning, causal inference, and network science. As the scientific literature grows, informal peer networks are no longer an adequate mechanism for helping researchers figure out which questions are most worth working on. Prashant made a careful case for formal, statistically-grounded prioritization mechanisms.
Niveditha Iyer
Niveditha studied CS at Stanford and has worked on AI-assisted drug discovery at the Broad Institute and D.E. Shaw Research; she now works on continual learning and human-agent collaboration. Her proposal articulates how the scientific record systematically loses null results, which are really important for progress.
3rd Prize
Christina Ernst
Christina leads the Functional Genomics team at EMBL’s European Bioinformatics Institute, where she and her team build and maintain the open-access infrastructure she’s writing about fixing. Functional genomics keeps generating expensive data that effectively disappears, not because of scientific failure but because the coordination and standards infrastructure to make it reusable isn’t there. Christina mapped the specific mechanisms behind this and proposed concrete remedies.
Matthew Leighton
Matthew is a postdoctoral fellow at Yale’s Quantitative Biology Institute, applying tools from physics and mathematics to complex problems in biology. His essay explains how funding structures and incentives often push researchers to stay within their technical domains, but there could be more creative ways to explicitly enable multidisciplinary collaborations beyond box-checking exercises that are typical of many grants.
Harshu Musunuri
Harshu is a synthetic biologist and MD-PhD candidate at UCSF, working on bacteriophage engineering and the immune-microbiome interface. Her essay proposed that understanding the microbial roots of chronic disease could move medicine toward prevention. She believes that there could be a causal link between common pathogens and a range of chronic diseases, and reimagining funding and work around this goal could open up new critical insights.
What comes next
This essay competition generated an amazing public catalogue of concrete cases where there could be fundable solutions to metascience challenges. We’re still working through what that means for our own funding priorities at Astera. But the volume and specificity of what came in was enough to move our thinking on a few things.
All 187 essays whose authors consented to sharing are linked on our website. We’re grateful for their willingness to do this, and we have shared their organized entries with other funders and policy advocates. We will continue to pay attention to the dialogue happening through and around the submissions (yes, we’re reading comment sections!). We are also thinking through what the next iteration of this effort might look like in terms of another competition or a funding call, so stay tuned on that front.
 | A guest post by
|